
یادگیری ماشین (ML) نوعی هوش مصنوعی (AI) است که به برنامههای نرمافزاری اجازه میدهد تا در پیشبینی نتایج، دقیقتر شوند، بدون اینکه به صراحت برای این کار برنامهریزی شده باشند. الگوریتم های یادگیری ماشین از داده های تاریخی گذشته به عنوان ورودی برای پیش بینی مقادیر خروجی جدید استفاده می کنند.
موتورهای توصیه (Recommendation engines) یک مورد رایج برای یادگیری ماشین هستند. سایر کاربردهای محبوب استفاده از یادگیری ماشین عبارتند از:
- تشخیص تقلب (fraud detection)
- فیلتر هرزنامه (spam filtering)
- شناسایی تهدید بدافزار (malware threat detection)
- اتوماسیون فرآیند کسب و کار (business process automation)
- نگهداری پیش بینی (Predictive maintenance)
چرا یادگیری ماشین (machine learning) مهم است؟
یادگیری ماشین برای سازمان ها از این زاویه اهمیت دارد که به آنها دیدی از روند رفتار مشتری و الگوهای عملیاتی کسب و کار می دهد و همچنین از توسعه محصولات جدید پشتیبانی می کند. بسیاری از شرکتهای پیشرو امروزی، مانند فیسبوک، گوگل و اوبر، یادگیری ماشین را به بخش مرکزی عملیات خود تبدیل کرده اند. یادگیری ماشین برای بسیاری از شرکت ها به یک تمایز رقابتی مهم تبدیل شده است.
انواع مختلف یادگیری ماشین چیست؟
یادگیری ماشین کلاسیک اغلب بر اساس نحوه یادگیری الگوریتم در پیشبینی دقیقتر طبقهبندی میشود. چهار رویکرد اساسی وجود دارد:
- یادگیری تحت نظارت (Supervised learning)
- یادگیری بدون نظارت (Unsupervised learning)
- یادگیری نیمه نظارتی (Semi-supervised learning)
- یادگیری تقویتی (Reinforcement learning)
نوع الگوریتمی که دانشمندان دادههای الگوریتمی برای استفاده انتخاب میکنند بستگی به نوع دادههایی دارد که میخواهند پیشبینی کنند.
یادگیری نظارت شده یا تحت نظارت: در این نوع یادگیری ماشین، دانشمندان داده الگوریتمهایی را با دادههای آموزشی برچسبگذاری شده ارائه میکنند و متغیرهایی را که میخواهند الگوریتم برای همبستگی ارزیابی کند، تعریف میکنند. هم ورودی و هم خروجی الگوریتم مشخص شده است.
یادگیری بدون نظارت: این نوع یادگیری ماشین شامل الگوریتم هایی است که روی داده های بدون برچسب کار می کنند. الگوریتم، کل مجموعه داده ها را به دنبال هر گونه ارتباط معنی دار اسکن می کند. دادههایی که الگوریتمها روی آنها آموزش میدهند و همچنین پیشبینیها یا توصیههایی که الگوریتم تولید میکنند، از پیش تعیین نشدهاند.
یادگیری نیمه نظارت شده: این رویکرد برای یادگیری ماشین شامل ترکیبی از دو نوع قبلی است. دانشمندان داده ممکن است الگوریتمی را تغذیه کنند که عمدتا با دادههای آموزشی برچسبگذاری شده است، اما این مدل آزاد است که دادهها را به تنهایی کشف کند و درک خود را از مجموعه داده توسعه دهد.
یادگیری تقویتی: دانشمندان داده معمولاً از یادگیری تقویتی برای آموزش به ماشین برای تکمیل یک فرآیند چند مرحله ای استفاده می کنند که قوانین مشخصی برای آن وجود دارد. دانشمندان داده، الگوریتمی را برای تکمیل یک کار برنامه ریزی می کنند و به آن نشانه های مثبت یا منفی می دهند که چگونه کار را کامل کند. اما در بیشتر موارد، الگوریتم به تنهایی تصمیم می گیرد که چه مراحلی را در طول مسیر بردارد.
یادگیری ماشین تحت نظارت چگونه کار می کند؟
یادگیری ماشین نظارت شده به دانشمند داده (data scientist) نیاز دارد که الگوریتم را با ورودی های برچسب دار و خروجی های دلخواه آموزش دهد. الگوریتم های یادگیری نظارت شده برای کارهای زیر خوب هستند:
- طبقه بندی باینری: تقسیم داده ها به دو دسته
- طبقه بندی چند کلاسه: انتخاب بین بیش از دو نوع پاسخ
- مدل سازی رگرسیون: پیش بینی مقادیر پیوسته
- گروه بندی: ترکیب پیشبینیهای چندین مدل یادگیری ماشین برای تولید یک پیشبینی دقیق
یادگیری ماشین بدون نظارت چگونه کار می کند؟
الگوریتم های یادگیری ماشین بدون نظارت نیازی به برچسب گذاری داده ها ندارند. آنها داده های بدون برچسب را غربال می کنند تا به دنبال الگوهایی باشند که می توانند برای گروه بندی نقاط داده در زیر مجموعه ها استفاده شوند. اکثر انواع یادگیری عمیق، از جمله شبکه های عصبی، الگوریتم های بدون نظارت هستند. الگوریتم های یادگیری بدون نظارت برای کارهای زیر خوب هستند:
- خوشه بندی: تقسیم مجموعه داده ها به گروه ها بر اساس شباهت
- تشخیص ناهنجاری: شناسایی نقاط داده غیرعادی در یک مجموعه داده
- ارتباط کاوی: شناسایی مجموعه ای از آیتم ها در یک مجموعه داده که اغلب با هم اتفاق می افتد.
- کاهش ابعاد: کاهش تعداد متغیرها در یک مجموعه داده
یادگیری نیمه نظارتی چگونه کار می کند؟
یادگیری نیمه نظارت شده توسط دانشمندان داده کار می کند که مقدار کمی از داده های آموزشی برچسب گذاری شده را به یک الگوریتم تغذیه می کنند. از این طریق، الگوریتم ابعاد مجموعه دادهها را میآموزد و سپس میتواند آنها را روی دادههای جدید و بدون برچسب اعمال کند.
عملکرد الگوریتمها معمولاً زمانی بهبود مییابد که روی مجموعه دادههای برچسبگذاری شده آموزش ببینند. اما برچسب زدن داده ها می تواند زمان بر و پرهزینه باشد. یادگیری نیمه نظارتی بین عملکرد یادگیری تحت نظارت و کارایی یادگیری بدون نظارت قرار می گیرد. برخی از زمینه هایی که در آن از یادگیری نیمه نظارتی استفاده می شود عبارتند از:
- ترجمه ماشین: آموزش الگوریتم ها برای ترجمه زبان بر اساس کمتر از یک فرهنگ لغت کامل از کلمات
- تشخیص تقلب: شناسایی موارد تقلب زمانی که فقط چند نمونه مثبت داشته باشید.
- برچسبگذاری دادهها: الگوریتمهایی که روی مجموعههای داده کوچک آموزش داده شدهاند، میتوانند یاد بگیرند که برچسبهای داده را به طور خودکار به مجموعههای بزرگتر اعمال کنند.
یادگیری تقویتی چگونه کار می کند؟
یادگیری تقویتی با برنامه ریزی یک الگوریتم با یک هدف مشخص و مجموعه ای از قوانین تجویز شده برای دستیابی به آن هدف کار می کند. دانشمندان داده همچنین الگوریتم را طوری برنامهریزی میکنند که وقتی عملی را که برای رسیدن به هدف نهایی مفید است دریافت میکند به دنبال پاداشهای مثبت باشد. و وقتی عملی را انجام میدهد که آن را از هدف نهایی دورتر میکند مجازات دریافت میکند.
یادگیری تقویتی اغلب در زمینه هایی مانند:
- رباتیک: ربات ها می توانند با استفاده از این تکنیک انجام وظایف دنیای فیزیکی را بیاموزند.
- گِیم پلی ویدیویی: از یادگیری تقویتی برای آموزش ربات ها برای انجام تعدادی بازی ویدیویی استفاده شده است.
- مدیریت منابع: با توجه به منابع محدود و یک هدف تعریف شده، یادگیری تقویتی می تواند به شرکت ها در برنامه ریزی نحوه تخصیص منابع کمک کند.
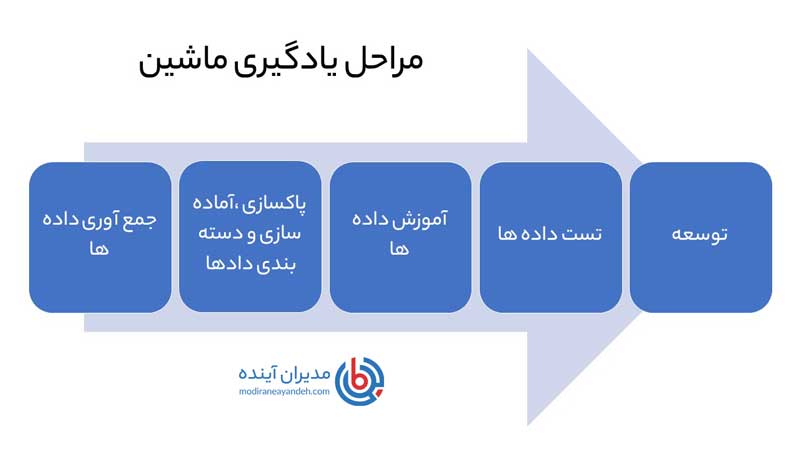
چه کسانی از یادگیری ماشین استفاده می کنند و برای چه مواردی استفاده می شود؟
امروزه یادگیری ماشین در طیف وسیعی از کاربردها استفاده می شود. شاید یکی از معروفترین نمونههای یادگیری ماشین در عمل، موتور توصیهای باشد که فید خبری فیسبوک را تامین میکند.
فیس بوک از یادگیری ماشین برای شخصی سازی نحوه ارائه فید هر عضو استفاده می کند. اگر عضوی مکرراً برای خواندن پستهای یک گروه خاص توقف کند، موتور توصیه شروع به نمایش بیشتر فعالیت آن گروه در فید میکند.
در پشت صحنه، موتور در حال تلاش برای تقویت الگوهای شناخته شده در رفتار آنلاین اعضا است. اگر عضو الگوهای خود را تغییر دهد و نتواند پستهای آن گروه را در هفتههای آینده بخواند، فید اخبار مطابق با آن تنظیم میشود.
علاوه بر موتورهای توصیه، کاربردهای دیگر برای یادگیری ماشین شامل موارد زیر است:
- مدیریت ارتباط با مشتری. نرمافزار CRM میتواند از مدلهای یادگیری ماشین برای تجزیه و تحلیل ایمیل استفاده کند و اعضای تیم فروش را ترغیب کند که ابتدا به مهمترین پیامها پاسخ دهند. سیستم های پیشرفته تر حتی می توانند پاسخ های بالقوه موثر را توصیه کنند.
- هوش تجاری. فروشندگان ابزارهای هوش تجاری (Business Inteligent) و تجزیه و تحلیل از یادگیری ماشین در نرم افزار خود برای شناسایی نقاط داده بالقوه مهم، الگوهای نقاط داده و ناهنجاری ها استفاده می کنند.
- سیستم های اطلاعات منابع انسانی. سیستمهای HRIS میتوانند از مدلهای یادگیری ماشین برای فیلتر کردن برنامهها و شناسایی بهترین گزینه از میان افراد واجد شرایط برای یک موقعیت باز استفاده کنند.
- ماشین های خودران. الگوریتمهای یادگیری ماشین حتی میتوانند این امکان را برای یک خودروی نیمهخودران فراهم کنند که یک شی که امکان مشاهده آن توسط راننده سخت است را تشخیص داده و به راننده هشدار دهد.
- دستیاران مجازی. دستیارهای هوشمند معمولاً مدلهای یادگیری ماشین تحت نظارت و بدون نظارت را برای تفسیر گفتار طبیعی و زمینه عرضه ترکیب میکنند.
نکات کلیدی
یادگیری ماشین، زیرشاخه ای از هوش مصنوعی است که به طور کلی به عنوان توانایی ماشین برای تقلید از رفتار هوشمند انسان تعریف می شود. سیستمهای هوش مصنوعی برای انجام وظایف پیچیده به روشی مشابه نحوه حل مشکلات انسانها عمل می کنند.
4 نوع یادگیری در یادگیری ماشین عبارتند از:
- یادگیری تحت نظارت
- یادگیری بدون نظارت
- یادگیری نیمه نظارتی
- یادگیری تقویتی
یادگیری ماشین در صنایع مختلف منجر شده است که در پیشبرد پروژه های تحول دیجیتالی و جسورانه اقدامات ارزشمندی انجام پذیرد.








